Transform Schema
urn:js:virtue:aspire:proposal:10.1
TL;DR
Use of the Transform Schema for managing transformation SQL
Rational
There are a number of mechanisms for holding and running SQL within Snowflake to populate data into the RDV, BDV and PL areas. Some teams have embedded the SQL into lambda’s others use views held in BDV areas, in some instances SQL is embedded in Ab Initio jobs. The result is that tracking lineage across and within teams is a challenging exercise raising the risk that impact assessment and support will be a complex and time consuming undertaking. Currently the only centralised place where lineage is stored is the mapping documentation source to target specs which should be the master for business logic transformation but do not detail all the objects and data sets involved in the actual ETL processes.
This page sets out a proposal to adopt one shared approach across all teams as the environment takes on greater focus as part of migration towards Tier 1 support levels. The proposal only applies to SQL based transformation for data loads that are following the pathway from S3 to staging and then on into the PL. Other patterns may be required, to accomodate streaming data flows for example, in which case these should be considered against the approach detailed below for opportunities to align.
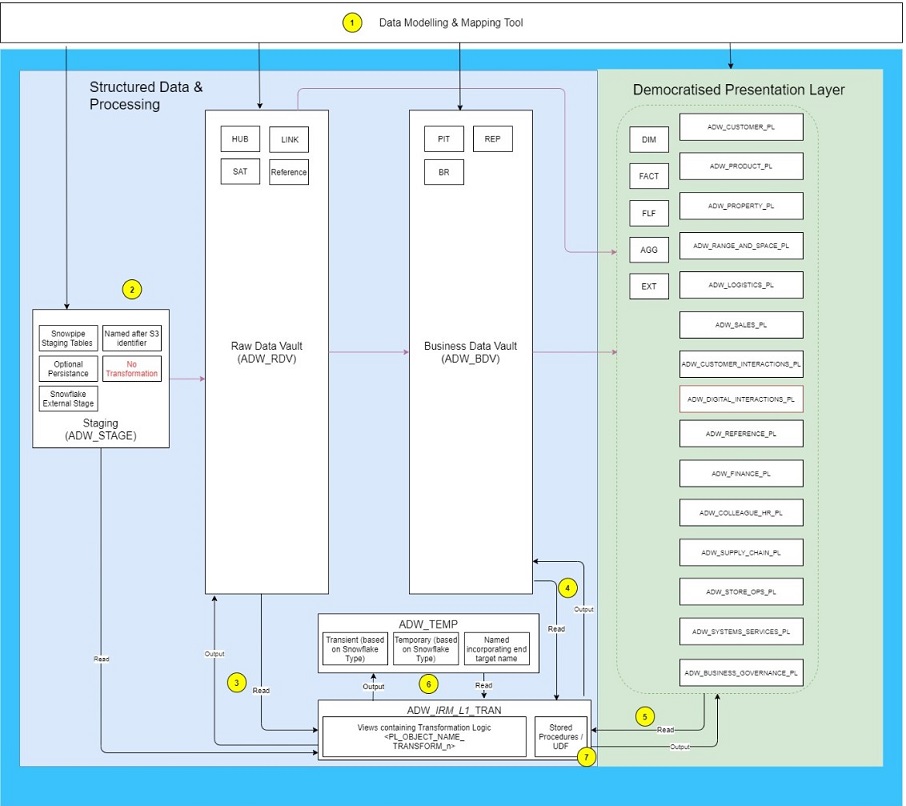
- The master for DDL used to create objects in Stage, RDV, BDV and PL schemas is GitHub although this DDL is frequently fed from data models mastered in WhereScape
- Initial data loads into Snowflake will come through the Staging tables where unnecessary data should be removed if possible. The data is frequently held in JSON schemas in a single attribute.
- Loads into the RDV extracting data from stage should have the corresponding SQL logic stored as views in the relevant transform schema
- Loads into the BDV should have corresponding SQL logic stored as views in the relevant transform schema
- Loads into the PL should have the corresponding SQL logic stored as views in the relevant transform schema
- Temporary tables may be required to manage complex tranformations or for performance reasons, these must be stored in the ADW_TEMP schema and must be named incorporating the final target, detailed naming standards are still required. Data must not be be persisted in this area for significant periods of time.
- Snowflake stored procedures should be implemented with the Transform schema relevant to the IRM area they are loading data into. This provides support teams with a central place to access procedural logic if required.
Adopting some common standards to transformation in Snowflake allows the following benefits to be realised
- Views held within the Transform schemas used directly for impact assessment by the teams owning the logic
- Extracting data from a single place and creating lineage maps allows gaps in the overall picture of lineage to be identified
- Provides the easiest method of capturing lineage from SQL when compared with extracting data directly from the query history tables
- When supporting teams or swarms need to identify how business logic is being applied they can analyse all transform objects in one place rather than crawling multiple git repos each with different structuring approaches
Several options exist for capturing lineage from SQL scripts, https://sqlflow.gudusoft.com/#/ is currently being investigated.
Benefits
Impact analysis
Without
The only way to perform impact analysis is to search all git repos. This is difficult and prone to inaccuracy.
With
It will be possible to search a single git repo (that of the transform schema).
Compile time safety
Without
The impact of refactoring database objects can only be measured by running the entire Aspire test suite. This is an onerous and difficult as it would require every squad to test every end-to-end pipeline.
With
Database objects can be refactored and then using a CICD pipeline the ADW rebuilt from scratch. If the ADW schema is invalid then the CICD pipeline will fail.
This will allow for faster development and deployment cycles.
Data lineage is easier
Without
The data lineage computation will need to extract queries from the query history log. Although technically possible this is a complex task, and aligning the queries with the version of the database schema is difficult.
With
The data lineage for an end-to-end data pipeline can be extracted from the database schema and can therefore be aligned with the schema version.
Implications
Why can’t we just select the query data from the query history tables in Snowflake?
Although the query history data in Snowflake will contain all the SQL executed there are a few reasons why it is likely to be complex to interpret:
- Some ELT loads run SQL very frequently so there could be large volumes of data to sift through
- Where views are being executed it may be complex to link these with the associated insert or merge statements then used to load data into physical tables
- Understanding which users are used to run queries and how these relate to individual teams allowing only queries used for ETL to be captured is a complex task and requires ongoing management.
- Where versions of logic have changed then understanding which is the most current version is challenging from query history logs.
How does this approach capture the step to insert data into the target table providing full source to target visibility?
Basic data flow for inserting into an RDV Satellite Key: Orange: Physical table, Green: View, Blue: Insert statement, Purple: Load process
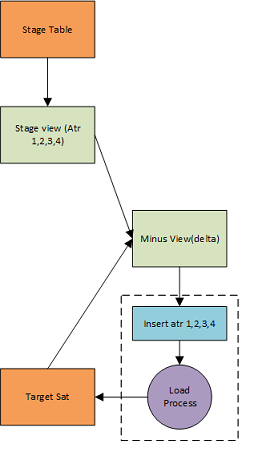
Steps shown:
- Data is loaded into a staging table in JSON format
- The JSON data set is flattened via a view so it can be compared with the target table
- A view containing a minus between data sets retrieves the differences in keys and supporting metadata
- The load process extracts from the view comparing data sets and inserts new rows into the target satellite.
There are many ways of achieving the same results as the simple load process shown for example both the flatten commands and minus statement could be included in the same view but the aim is to show where views would be used in the process. A SQL statement to insert data into the final target table will still be required but this can be very simple and embedded in the load process used by the team responsible for the data. To avoid missing the final step in the lineage, i.e the actual insert, a naming convention should be adopted highlighting the target destination for each view if it is a physical table. In the example above this Minus view might be named V_INSERT_TARGET_SAT, this can be used for lineage extraction and also parsed against table names to find potential orphans.
This adds to deployment complexity as all SQL containing business logic will now need to be deployed into the database
Ideally teams will have included deployment into Snowflake within their CI/CD pipelines so that their database releases are as simple as other pathways. If this is not the case then fixing the deployment issues for Snowflake is something that should be considered separately. By separating the SQL logic from the orchestration frameworks could be seen as decoupling different aspects of the ETL which could have benefits for speed of change as the environment matures.
How does this impact the use of tasks and stream?
Streams operate on tables and can then be retrieved through views like other data sources so use of the transform schema should not impact this area.
Does this impact the load pipeline or orchestration mechanisms I already have in place
Storing views in this way should not impact the way in which ETL pipelines are constructed or orchestrated. However, migrating existing pipelines across to the transform schema could be undertaken gradually as changes are made to associated areas. This would require discussion between the delivery squads and support teams.
My SQL is embedded in stored procedures how would this work with the transform schema?
The core logic contained within the SQL would be migrated into a view within the transform schema and a much simplified SQL statement included selecting the relevant columns from the appropriate view. Any WHERE clause values dynamically populated within the procedure would be run against the SQL selecting from the view
Does this mean that everyone needs to follow the same standards, what would these be and how would they be monitored?
The naming standards will be created and included in this page after the first set of reviews.
What about ELT pipelines that are not using SQL to transform or join data
The majority of transformation processess loading data into the RDV, BDV and PL layers in Snowflake use SQL to transform data. If external functions or called or transformation processing occurs directly in streams then alternative methods would be required to capture this lineage. Using the transform schema is intended to address the majority of processes first.
How would the data be extracted for publication?
Multiple options are available one being investigated is https://sqlflow.gudusoft.com/#/ although graph databases may also be used to hold lineage relationships
If Snowflake tables are treated as contracts for consumers from other teams to take data from then is lineage required?
ASPIRE has thousands of tables which exist as part of a single system providing integrated data for analytics and reporting. Utilising the concept of contracts between teams is very useful and will lead to greater autonomy but for support, audit or impact assessment understanding lineage from ingest to publication, something that may involve several teams, is key to providing the required levels of service.