Data Federation Principles
urn:js:virtue:aspire:proposal:25.1
TL;DR
These are the options for the approach and principles of data federation
Rational
Data platform development rarely occurs in complete isolation with brand new requirements, data sets and calculations. More often than not there will be a number of existing data repositories which are likely to be used in a variety of processes potentially including operational activities. This presents the teams responsible for building a new analytical/visualisation repository with a significant challenge when looking at options to migrate data consumers from existing repositories. Until all data requirements have been met from the new system, including amongst others agreed metric calculations, historical data availability, latency, SLAs, data transformation routines with signed off outcomes and perhaps most importantly data entity and attribute coverage, consumers cannot be fully migrated. As a result there may well be a protracted period when data is consumed from the legacy environment in combination with a growing amount of data from the new system, resulting in federation of data across environments. If more than one data platform is being retired (there are many to consider in Sainsbury’s) then the challenges associated are multiplied in complexity and number. This page covers ways in which challenges associated with federation can be addressed and defines some principles to help manage the process.
Option 1 - Publication of new and legacy data sets in parallel
From an immediate delivery perspective the simplest approach for deploying a new data platform is to make the new data available in parallel with existing data sources. In this scenario users can access both new and legacy data sources for their calculations. Provided the teams responsible for publishing new data sets clearly communicate what is covered in legacy by each delivery then end users can migrate their workloads incrementally to the new data and structures. Implicit in this approach is an agreement that the user community will create points of integration between existing and new data sets each of which may apply separate sets of rules to manage the separate data sources and calculations. Each of these points of integration is likely to evolve separately and therefore produce different results, they will also require management of change in both data and data structures across multiple bespoke code sets within the user communities for each migration from legacy to new. The engineering teams migrating data consumers to the new data sources will as a result need to manage not only changes between the legacy and new data structures and values but also transformation logic which has arisen within the federation points. Technically there are also likely to be challenges where data is being consumed from different technologies as this information will need to be transferred into user controlled federation environments multiple times requiring engineering support and additional complexity for data consumers. There are also likely to be cases where data is shared between the various user maintained federation points.
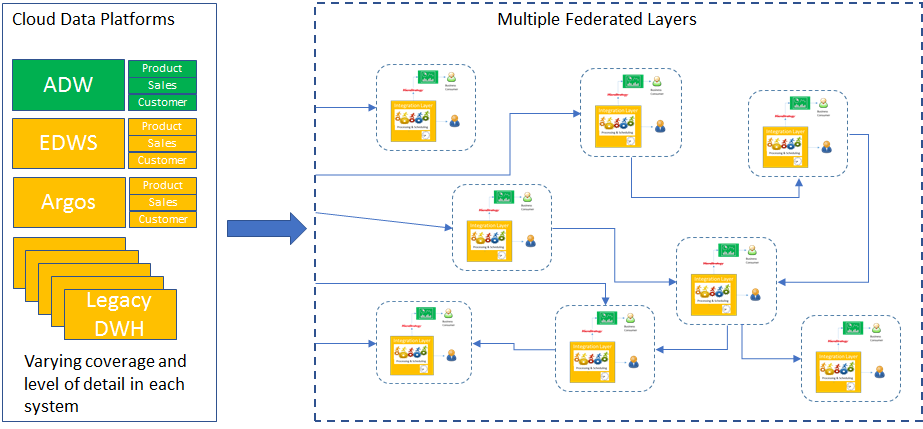
Option 2 - Migration to common technical platforms
To address the technical challenges arising from integrating data across various networks and technologies it may be possible for the central engineering teams to either lift and shift data processing or alternatively replicate data sets into a storage and data processing technology. In this way the challenge faced by data consumers around copying data from multiple technologies is reduced and should therefore result in greater opportunity to make use of available data sets from both new and legacy systems. There are existing examples of this approach for EDW and some of the Argos Planning Inc single customer view. However, many of the data integration complexity challenges covered within Option 1 still remain.
Option 3 - A single federation layer
There are three key areas to consider when migration from legacy data platforms: 1) Technically connectivity and movement of data, 2) Data Structures 3) Data values and aggregation (source pipelines). Option 1 above places responsibility for all three with the user community, although a significant amount of support from engineering teams will be required to achieve migration. Since the target to migrate from legacy is likely to be an objective against the engineering teams complexity to achieve this should be considered. Option 2 deals with some of the challenges associated with consideration 1 but does not address either of the others.
To simplify the user landscape during the migration phase a single access point can be published for data consumers, in this way the data structures can be maintained at a single point even if the data being published is taken from legacy data platforms. This addresses considerations 1 and 2 leaving the engineering teams and data consumers to migrate across data feeds incrementally.
Delivery of a single federation layer is a challenging objective and requires a number of things to be in place for success:
- Agreement from the user community to migrate their access points from existing to new data structures even if these will publish the same data content. Without this a single federation layer will not be adopted.
- A target data structure representing as closely as possible the end state data structure for data from the legacy data sources, integrated with new data deliveries. This provides a consistent model against which the federation layer can be constructed.
- Engineering team ownership for target data structures and a mapping between these and the data sets sourced from legacy data platforms. This will allow ownership of data feed migration activities, incrementally moving towards the new feeds from legacy managed independently by separate engineering teams.
- Case studies and a common set of definitions and language to increase engagement with the data consumer community. The items in the federation layer (facts and dimensions) need to be defined and understood in a consistent way to facilitate adoption.
- An initiative to migrate data consumers to a federated data layer in fairly short timescales to reduce the risk of multiple user controlled federation layers being developed whilst moving across.
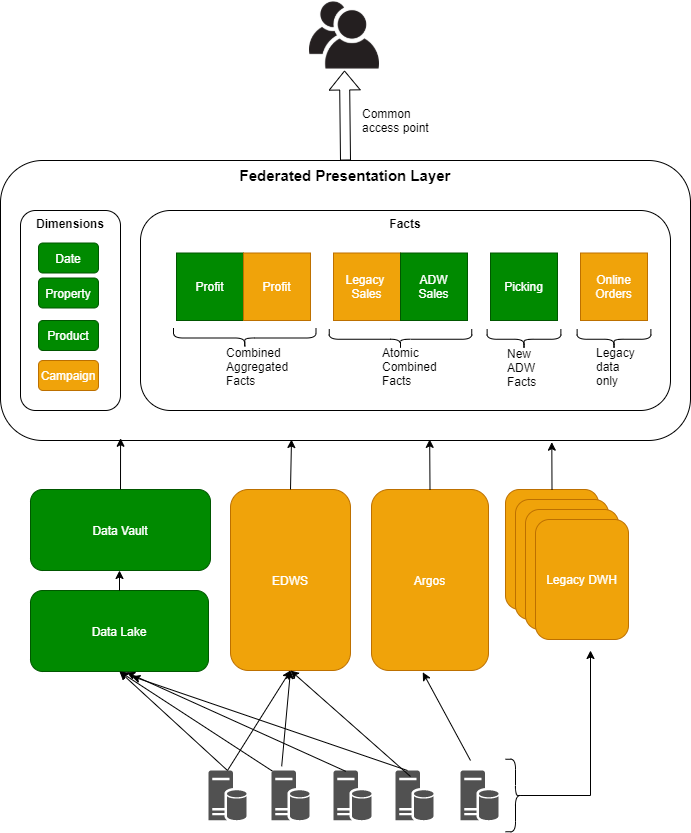
Publication of data to the federation layer will need to consider several scenarios:
| Scenario | Action |
|---|---|
| Data is sourced from a new source not available within the legacy data systems | Create data structures and publish data in line with agreed data structure guidelines and standards |
| Data sets from legacy data platforms contains descriptive elements (Dimension entities and attributes) in addition to metrics or facts, some of these Dimensions have already been delivered strategically. | As a general rule metrics should only be brought into the federated layer from legacy data platforms in combination with keys to reference data rather than including descriptive elements. The keys can then be used to join with descriptive attributes which have been delivered strategically, for example if a metric table contains SKU as well as product description but the strategic Product Dimension is keyed on SKU then only the metric SKU should be published into the federated layer. Where legacy tables only contain descriptive elements but no associated keys then very minimal changes should be investigated to understand whether the associated keys can be brought into the legacy presentation layers. As a last resort the descriptive items should be copied into the federated layer directly, the ownership and migration of these will be defined at this point. Where descriptive elements and associated keys are not available from strategic source but do exist in legacy platforms then these should be sourced separately into the federated layer as dimensions. |
| Data in legacy is aggregated and cannot be broken down to the level of grain available through strategic feeds if these exist. | In this instance the first step should be to create a view of the minimum set of required metric data at the defined grain. Secondly the strategic feeds should be used to generate an aggregated view of data at the same level of grain as legacy. Both sets of data should be presented side by side with the same dimensional keys. This will allow data consumers to migrate between sources without drastic change to their codebases and also provides a clear set of information for reconcilliation between legacy and strategic. |
| Metric/fact data is available in similar structures from both legacy and strategic sources but from different channels or brands. | In this instance the data should be loaded into the same federated data structures with one set of data inserted after the other with the same level of granularity and dimensional key attributes. For example a sales feed fact with one row per till, operator, product sale line item by date and time might be sourced strategically for food transactions but from legacy platforms for Argos, in this case both feeds should be loaded into the same fact table. This will allow users to provide aggregated views of information easily across brands and reduce the impact as new strategic feeds become available. |
| Data is not available from strategic sources | In this instance data should be loaded into facts and dimensions for measurement and descriptive data respectively. |
The diagram below shows the various scenarios that will need to be taken into account:
Implications
None.
Appendix
Migration from link