Clone Based Feature Engineering And Testing
urn:js:virtue:aspire:proposal:12.2
TL;DR
Look to remove dependance on persisted environments and replace them with clones that have been created especially for the task in hand.
Rational
Current situation
At present we have persisted development and preprod environments that are used for pipeline and feature engineering and testing. These environments hold a lot of old data (non-prod and prod) and stale objects which add to overall storage and management costs but do not deliver benefits to match.
Proposal
Rather than maintaining these persisted development and testing environments we could consider removing them and replacing them with clones that exist for the duration of any particular exercise, such as a piece of development or testing. Clones could be created for a single squad and sprint, a family for a family-wide exercise or across families where testing of cross-family/IRM pipeline dependencies is needed.
Being timeboxed they would incur minimal storage costs which would relate to the data loaded during the exercise. Any clone should be removed or refreshed before it starts to reserve data partitions that have exceeded the production retention period.
Clones would be from the production environment and where required, loaded with new production data in line with the original production environment.
Benefits
- Working with production data will speed up delivery and remove rework due to sub-standard development data
- Temporary objects and data created as part of development and testing activities will be removed along with the clone so housekeeping by design
- Reduced conflict and risk of damage through removal of shared environments
- Improved visibility of devops costs through clone cost reporting
- Eventual cost savings through removal of persisted development and pre-production environments
- Using production data will allow for early visibility of enhancements to consumers via the clone without affecting production
- Supports a fail-fast and try again culture
- Having a clone that is aligned with production allows for testing between the clone and production to ensure unexpected changes do not occur
- Time consuming deployments can be made on a clone and swapped into production thereby decreasing production downtime and risk
- Clones will automatically be data retention compliant once Heimdallr is live
Dependencies
- Deployment pipelines that can target specific databases
- Ability to run concurrent Orchestration DAGs against different database targets
- Assessment and potential change to Munin so we manage a single version of classification for a schema object that will be applied to all environments
- Assessment and potential change to Barbossa to enable appropriate levels of access to clones for roles
- Clone management process to manage the creation, refresh, destruction and reporting for cloning
Supporting Virtues
The following virtues would support this proposal:
- (Principle) Production data is used for development activities
- (Standard) Automated Snowpipe is used to load data from S3 Raw -> Staging (this will allow for easy population of clones using production data)
Example
The following diagram shows some example cloning scenarios.
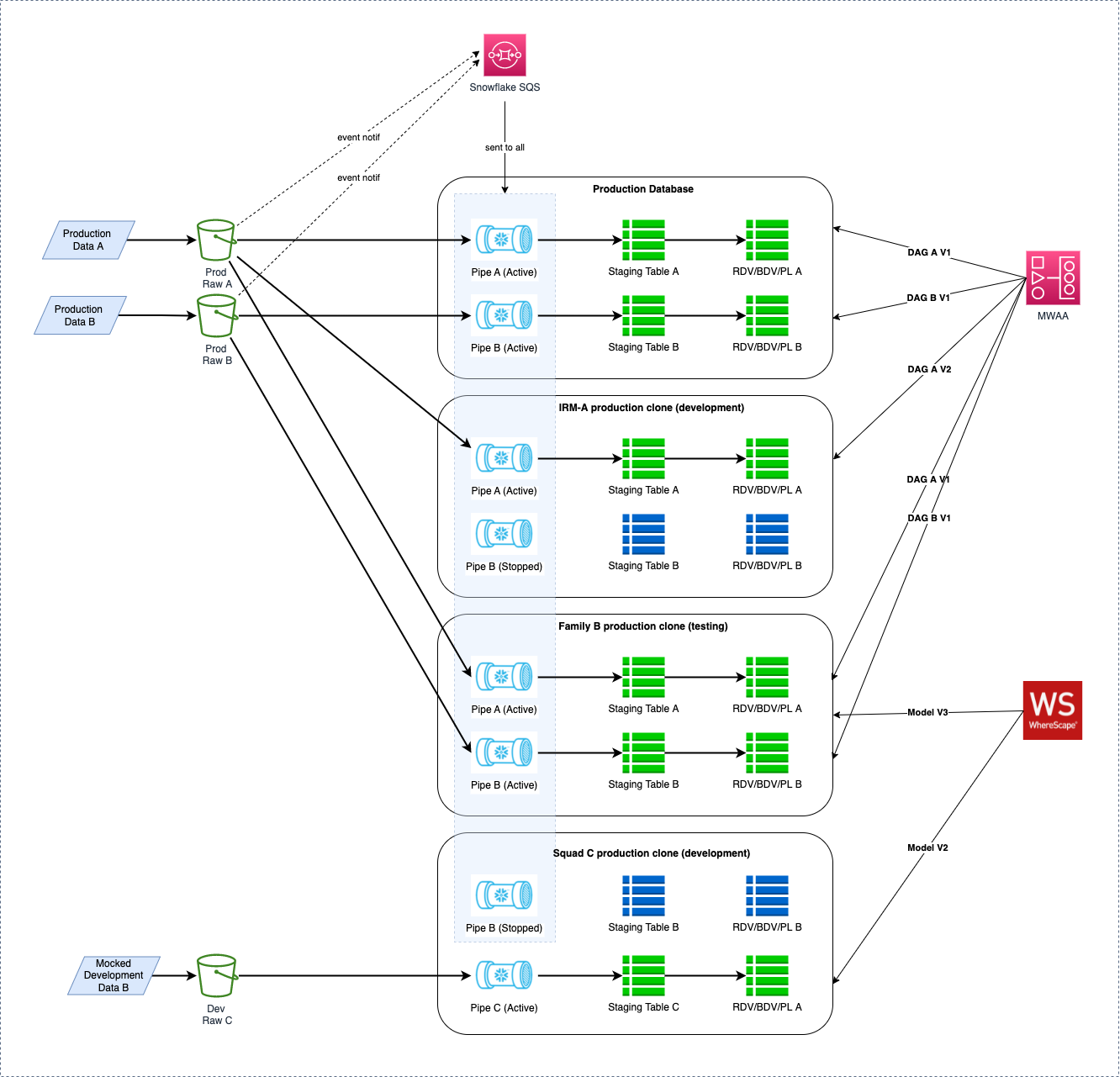
Details
- IRM-A Production Clone (development)
- Some development around the data coming in via Pipe A with no need for current data through Pipe B
- Pipe A is restarted and refreshed allowing for new production data to flow through
- DAG for orchestrating Pipe A data has been updated
- Family B Production Clone (testing)
- Testing of changes made to the models that hold data A and B
- Pipes A and B have been restarted and refreshed allowing for new production data to flow through
- DAGs unchanged so current version (V1) being run to bring data through to the RDV, BDV and PL
- Squad C Production Clone (development)
- No production data available so development data is mocked and a new pipe deployed to the clone
- Models created and transform units and sets developed
- No orchestration required - all manual
- Development data may be integrated with static data from source B given combined PL required
Implications
This is a significant change to WoW but can be rolled out incrementally alongside existing process.