ASPIRE Data Model Principles
urn:js:virtue:aspire:principle:36.1
TL;DR
These are the Principles that each of the ASPIRE data models must adhere to. The principles are based on the best practices of data modelling production and provide guide rails for the ASPIRE Data Model Standards.
Rational
Delivering a large and complex programme such as ASPIRE involves basing the deliveries on sound design principles.
There are a number of Data Models used throughout the ASPIRE eco-system. Some are owned and maintained by the Information Architect and some are owned and maintained by the Data Modelling team.
A summary of the ASPIRE Data Models is as follows:- 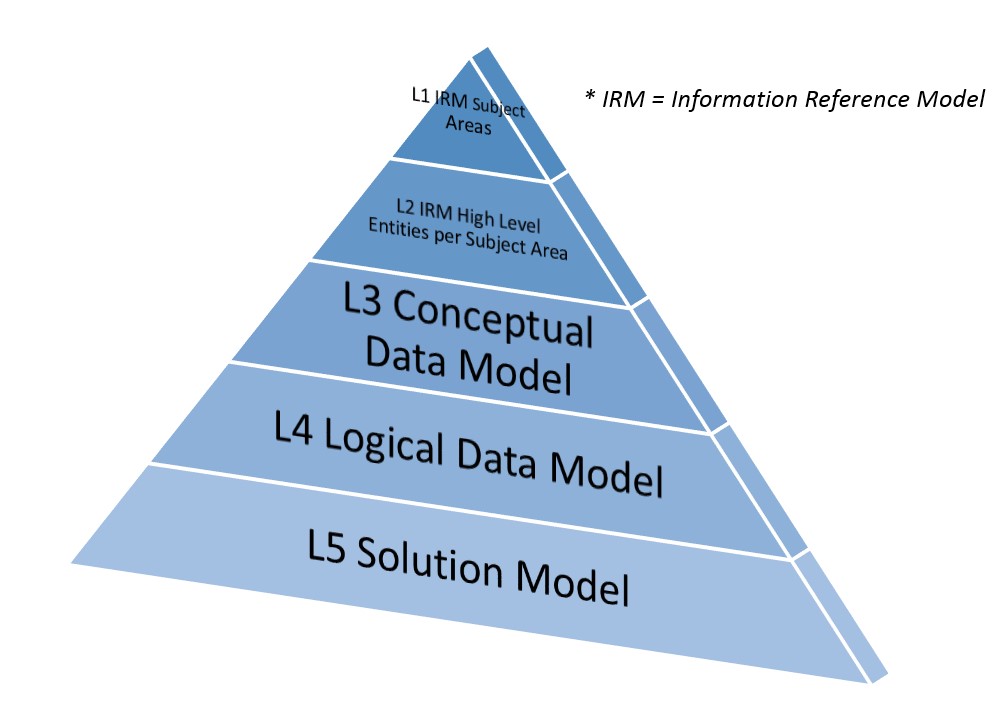 Figure 1: ASPIRE Data Model Layers
Figure 1: ASPIRE Data Model Layers
These Principals cover the models owned by Data Architecture:
- The L4 model is used to understand and document business understanding, scope and requirements.
- The L5 model is used as part of the detailed design and development delivery.
Implications
Failure to adhere to the Principles and the associated Standards will result in a high risk that the Aspire project fails to deliver the desired outcome. To support the ambition to have a single, democratised dimensional layer it is essential that consistant design Principles and Standards are defined, regularly reviewed and adherence is audited.
Appendix
L4 Logical Model Principles
Purpose of the model
The L3 Conceptual Model gives an Enterprise Level perspective of the Sainsbury’s data landscape. The L4 Logical Model will build upon the Conceptual Model and increase the detail to drive understanding into the development activities.
The Logical Model will be used to document the Entity, Attribute and Relationship requirements in enough detail to enable a Data Modeller to produce a Solution Data Model.
The Logical Model is not physicalized but it will be used:-
- During project delivery to test that each of the changes made to this model represent a business requirement and ensures each change has been reflected in the structure and mappings into the Solution Data Model.
- Is a structured and unambiguous notation to use when speaking to business customers about the data we hold within ASPIRE.
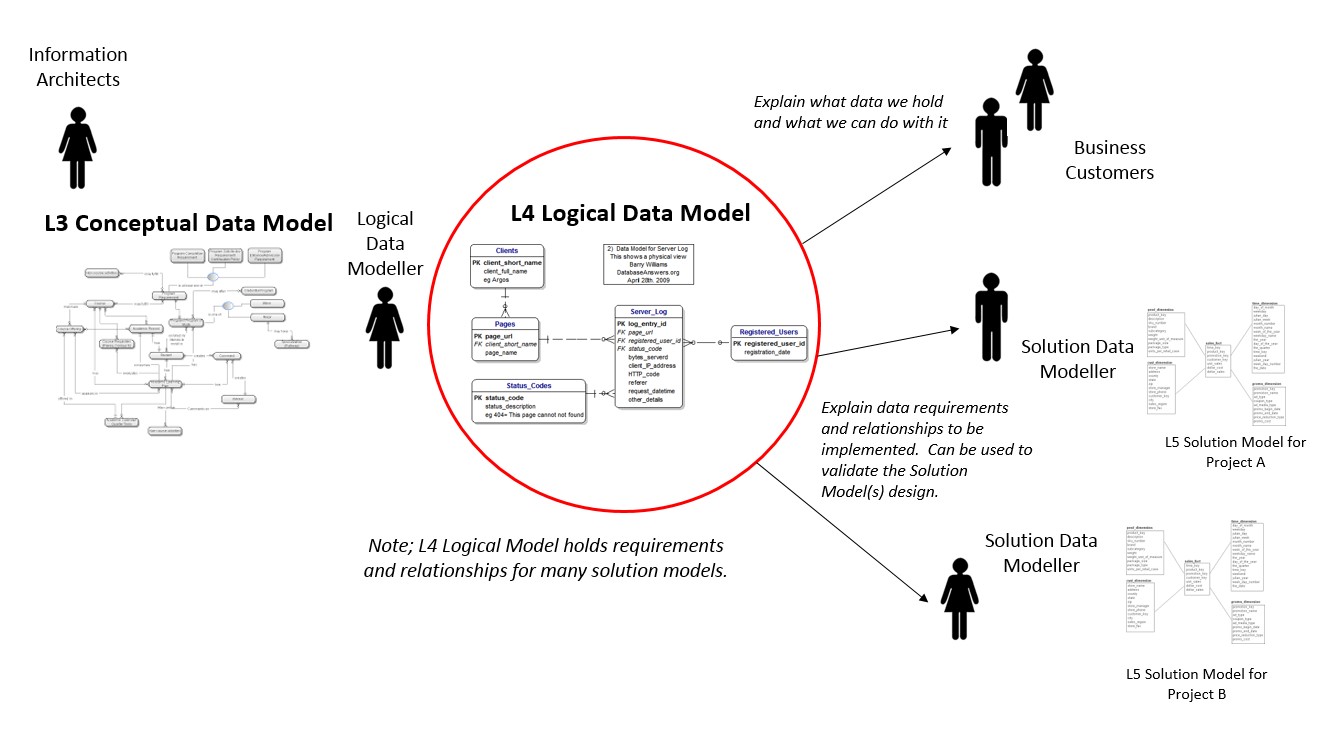 Figure 2: Use of the L4 Logical Model
Figure 2: Use of the L4 Logical Model
For brevity, from now on the L3 Conceptual Data Model will be referred to as the L3 Model, the L4 Logical Data Model will be referred to as the L4 Model and the L5 Solution Model will be referred to as the L5 Model.
Model Principles
This sub-section details the Principles behind why ASPIRE needs a L4 Logical Data Model:-
-
The L4 Model is a technology independent representation of the Sainsbury’s data activities and relationships and will be built up in house to document for both technical and non-technical users what data the ASPIRE data models hold. For example, if someone asks “What data do we hold about Sales Transactions in ASPIRE?” the L4 Model will answer this in a lower level of detail than what is held in the Information Architecture L3 Model
-
The L3 Model is the master and roadmap for the content of the L4 Model
-
Major changes to the L3 Model must be reflected in the L4 Model and visa-versa
-
The Entities within the L4 Model will always inherit the meaning/description from the L3 Model Entity
-
The L4 Model will cover functionality implemented by the L5 Model. As described below, the L5 Model covers the flow of data through both Integration and Presentation Layers, but the L4 Model has no concept of these different layers
-
Changes cannot be made to the L4 Model unless they are also represented in the L3 Model. As the L3 Model matures there will be projects that deliver changes to the solution models, i.e. the L4 Model and L5 Model that don’t require changes to the L3 Model
-
Meta-data will be built into the L4 Model to report on lineage between the L3 Model Entity and L4 Model Entities
-
One L3 Model Entity may be represented as one or more L4 Model Entities if the requirement necessitates further elaboration. This may especially be true in the areas of sub-typing and resolving many to many relationships
-
The L4 Model will introduce attributes to the Entities
- Each attribute will contain a business definition as defined by the Business Analysts
-
The L4 Model will introduce Subject Areas to break the model down into more focused areas that are easier to manage
-
All Relationships in the L4 Model will show the cardinality of the links between the dependent Entities
-
All Relationships in the L4 Model will have a business meaning for the link
-
Entities are keyed on Natural Keys. The choice about the use of Surrogate Keys, Hash Keys or Natural Key strategies is within the remit of the L5 Model
-
The L4 Model may contain changes that are not yet modelled in the L5 Model
-
The model will be maintained in ERWIN
- Within the L4 Model no overall single Entity Relationship Diagram will contain a summary of all of the Entities and Relationships because this is mastered in the L3 Model.
L5 Solution Model Principles
Purpose of the model
The L5 Solution Model will be used to define and generate the physical objects that make up the schemas that deliver the data throughout the ASPIRE eco-system. The Solution Model will contain, for example, definitions for tables, views, columns and the DDL generated will be used by the development teams to build the solution.
The L5 Solution Model will be split into specific Data Models that serve the following purpose:-
- Data Lake Data Model
- ADW Integration Layer Data Model
- ADW Presentation Layer Data Model.
The L5 Solution Model implements the requirements as defined in the L4 Logical Model.
The relationship between the three Solution Models introduced above is documented in the ASPIRE Target Architecture document owned by the Solution Architecture team.
At a high level the models are used at the following points within the ASPIRE eco-system:- 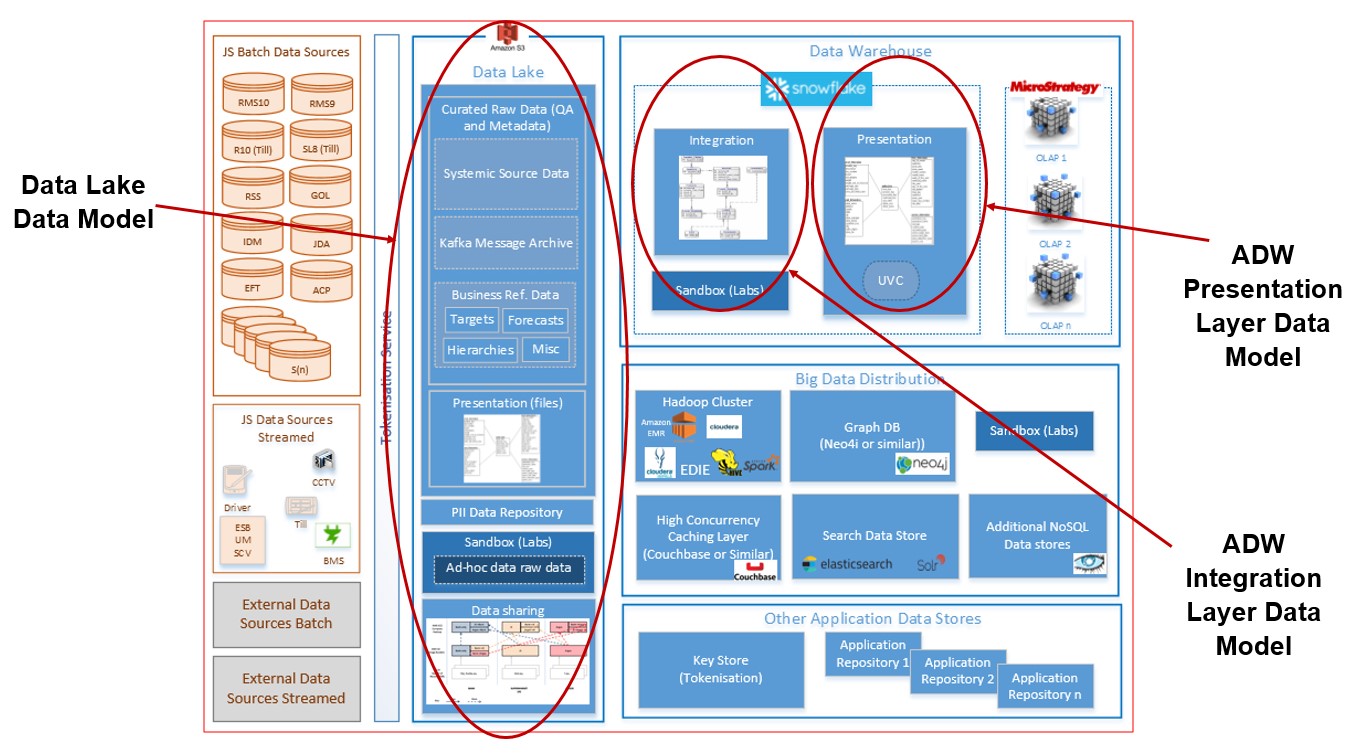 Figure 3: ASPIRE eco-system location of the different models
Figure 3: ASPIRE eco-system location of the different models
Data Lake Model Principles
This sub-section details the Principles behind why ASPIRE needs a L5 Data Lake Data Model:-
-
There must be understanding of what data objects are contained within the Data Lake. A list of all objects will be documented for the ASPIRE programme
-
Data objects will be segmented not by Subject Area but the parent S3 Bucket
-
Segmentation will also identify which data objects are within the Raw Layer, Curated Layer and which are within the Information Layer
-
Data copied from the ADW Presentation Layer into the Data Lake Information Layer will mirror the ADW Presentation Layer object structure
-
Data Quality at a row by row level will be performed on the files as they move from the Raw Layer to the Curated Layer
-
Data objects can be modified as they move between the different layers of the Data Lake, for example hash keys are generated and technical meta-data columns are added to enrich the data objects when landed in the Curated Layer
-
Data will be stored in a variety of formats at the discretion of the ASPIRE development team
-
All Data Lake data objects will have their meta-data uploaded to Alation.
-
Additional meta-data will be added once in Alation to align the data objects with the relevant L3 Logical Data Model entity.
The Data Lake principles implement the following DACE Data Management principles:-
-
Data Ingestion: Source Once, Use Many Times
-
Data Ingestion: One Way In
-
Data Ingestion: No Data Without Metadata
-
Data Ingestion: Retain As-Received Data
-
Data Processing: Process All Data
-
Data Processing: Store Record-Level Data
ADW Integration Layer Model Principles
-
The primary goal of the Integration Layer is to bring data into the ADW into a source system independent structure via internal common structures, concepts and language
-
The storage of the data will be modelled so as to avoid data silos
-
Data is loaded as presented from the curated Data Lake input sources
-
The granularity of the data in the Integration Layer will be at the lowest level of detail as supplied from the source systems
-
Very large sources of data, for example ClickStream web activity or detailed Sales Basket transactions will need to be saved to disk sparingly. All data will be written to the Integration Layer, the choice about whether to move this data to the Presentation Layer (e.g. a table) or virtualise the data (e.g. a view or internal Snowflake native format type) is a Presentation Layer decision
-
The model must enable agile development, so will be efficient in that reusable patterns can minimize modelling work and can be an enabler to reduce ETL development via the implementation of common framework components
-
The Integration Layer will be structured to add flexibility to meet both current and future requirements. This will be achieved by creating a data model that splits the decisions about where data is initially stored and how it is subsequently used
-
The structure must enable high performance parallel data loading of targets
-
Surrogate sequences will not be used as they introduce bottlenecks
-
Hash Keys will not be used as after analysis with Snowflake Consultants it has been advised they are not performant for joining very large datasets
- The drivers for the use of the Integration Layer model are:-
- Data Integrity – a primary goal of this model; define referential integrity and eliminate or strictly limit data redundancy
- Scalability – allow for increases in volume of data or the addition of new sources of data for existing business areas
- Flexibility – the design is not tied to one or more source systems, allowing for the flexibility to change the structure/sources of data being fed into this layer
- Consistency – a pattern based approach to data modelling will ensure all similar attributes will be held in the same places irrespective of the source feed being loaded
-
The model will be maintained in ERWIN
-
The model will be built using the Data Vault modelling pattern
-
As Data Vault is based on 3NF/normalised modelling, if no data is present then no default record will be created
-
All DDL for the Integration Layer will be generated out of ERWIN
- The schemas created by the development team must match the generated DDL
The ADW Integration Layer principles implement the following DACE Data Management principles:-
- Data Processing: Process All Data
- Data Processing: Store Record-Level Data
- Data Processing: Maintain Change History
- Data Processing: Create Consistent Keys
ADW Presentation Layer Model Principles
This sub-section details the Principles behind why ASPIRE needs a L5 Presentation Layer Data Model:-
- The primary goal of this layer is to enable a clear understanding of the data and ensure access of the data is performant depending on the tools used by the consumers
- The Presentation Layer can create separate target objects based on a single Integration Layer object, for example all customers are loaded into the same object in the Integration Layer but split into separate Argos and Nectar customers in the Presentation Layer. This is to reduce uncertainty and reduce filters/where clauses in the Presentation Layer
- The contents of the Presentation Layer are sourced only from the Integration Layer
- The Natural Key(s) from the Integration Layer will be carried over into the Presentation Layer
- The model will be built using the Dimensional modelling pattern – therefore denormalisation will be permitted in the Presentation Layer on a case by case basis. The Dimensional targets will be built upon a combination of the Raw Data Vault and Business Data Vault areas within the Integration Layer
- All major dimensions in the Presentation Layer will be historised with clear from/to date ranges available
- Historised Dimensions in the Presentation Layer must support intra-day refresh to give the customer’s the option of always seeing the latest data
- Minor dimensions in the Presentation Layer will not be historised
- All event level facts will have a date (and optionally time) available
- Snapshot (denormalised single row records) may be used where needed
- Data derived from business rules must only be calculated in one place and the result of the calculation made available in one place in the Presentation Layer for the use of different consumers. The Business Data Vault (part of the Integration Layer) will assist in achieving this
- The more complex business Entities, for example Customer or Item will be denormalised and sourced from potentially many Integration Layer objects into one or a smaller number of Presentation Layer objects. This will simplify the access of the data for the Presentation Layer tools and consumers but will involve data manipulation via a view or ETL development
- Snowflake (not the technology but the modelling technique) structures are to be minimised but will be considered on a case by case basis
- Redundant keys will be included on facts and aggregates to improve run-time performance when accessing the data. However late arriving data may necessitate the re-aggregation of affected objects
- Hierarchies will be collapsed into the relevant parent dimension
- All foreign keys are mandatory, the use of -1 for Unknown and -2 for Not Applicable must be followed
- The design and development team have the option of fully physicalizing the objects in the Presentation Layer. However in some cases, for example simple reference data or large transactional data sets the use of views can be chosen to provide a virtual object in the Presentation Layer
- The model should support some attributes within a historised dimension being non-historised; this can help reduce the number of type 2 Dimension rows created for a data element that changes often and is not need to be historised, for example OUTSTADING_DEBT on an Account dimension
- The model will be maintained in ERWIN
- Only a physical data model will be required due to the presence of the L4 Logical Data Model and the single target for ADW which is Snowflake
- All DDL for the Presentation Layer will be generated out of ERWIN
- The schemas created by the development team must match the generated DDL
The ADW Presentation Layer principles implement the following DACE Data Management principles:-
Data Processing: Store Record-Level Data Data Processing: Maintain Change History Data Provision: One Way Out Data Provision: Share Data Data Provision: Common Controlled Vocabulary